4. Probability (Discrete)#
# Import some helper functions (please ignore this!)
from utils import *
Context: As your first assignment at IHH’s ML team, you’ve been tasked with better understanding their Emergency Room (ER). Since you’re new, you’d first like to better understand how the ER works at a high level. Specifically, you’d like to answer questions like:
How many beings come to ER every day?
Overall, what conditions do the beings come to the ER for? (e.g. inflamed antenna, fever, etc.)
How many being remain hospitalized over night?
As such, today you’re carry out a preliminary “exploratory data analysis” (EDA).
Challenge: The answer to both of these questions cannot be given by a single number (e.g. the number of beings that come to the ER changes from day to day). So how can we give a deterministic answer to a question whose response is inherently variable or stochastic? Answer: probability distributions. Probability distributions are the basic building block that we will use to build complex ML systems.
Outline:
Introduce and practice the concepts, terminology, and notation behind discrete probability distributions (leaving continuous distributions to a later time).
Answer the above questions using this new toolset.
4.1. Terminology and Notation#
As in the spirit of all Computer Science classes, if we want the help of a computer to solve a problem, we need a language to precisely specify what we want it to do. In the same way that programming languages allow us to communicate to the computer a procedure we’d like it to execute, here, we will introduce the language—terminology and notation—from probability. In the future, we will translate statements in this language directly into code that a computer can run.
The terminology that we introduce here is slightly different from ones that you may have seen in a probability class. The reason for this is that we’re honing in on the minimal subset of terminology we need to describe a probabilistic ML model.
Random Variable (RV): A variable whose possible values are outcomes of a random phenomenon.
Example: Let \(N\) be an RV describing the number of beings that come into the ER on a given day.
Sample: A sample is a particular observation of the random phenomenon.
Example: On Monday, we observed \(N = 30\) (on Tuesday, this number will be different).
Sample Space or Support: The set of all possible values that an RV can take on. For discrete probability, this set must be “countable” (though this is not important for now).
Example: The sample space for \(N\) is the set \(S = [0, 1, 2, \dots, \infty)\), since we can have any integer from \(0\) to \(\infty\) (theoretically speaking) of beings come to the ER.
Probability Mass Function (PMF): A function mapping the outcome of an RV to the probability, or frequency with which it occurs. We can write the PMF as a mapping from the sample space to a number on the unit interval: \(p: S \rightarrow [0, 1]\).
Example: Let \(p_N(\cdot)\) denote the PMF of \(N\), where the dot represents an argument we have not specified. We denote the probability that \(N\) takes on a specific value \(n\) as follows: \(p_N(n)\). If we were told that \(p_N(5) = 0.1\), this means that the probability that exactly 5 beings came to the ER is 0.1 (or 10%).
PMFs have one notable property: the probability of all outcomes in the sample space must sum to 1.
Example: Continuing with the above example, we have that \(\sum\limits_{n \in S} p_N(n) = 1\).
Parameter: A parameter is a variable that controls the shape of the PMF.
Example: To illustrate this, suppose we chose to model the above phenomenon using a Poisson distribution. That is, \(p_N(\cdot) = \text{Poisson}(\lambda)\). To understand what we mean by parameter, it doesn’t matter what a Poisson distribution is, where it came from, and what it’s useful for. Instead, notice that a Poisson distribution relies on one variable, \(\lambda\) (its parameter), which controls the shape of the distribution. Specifically, \(\lambda\) determines the average of the distribution. \(\lambda = 10\) means that an average of 10 beings come into the ER on a given day. Ideally, the choice of \(\lambda\) will be informed by our domain knowledge and by data observed from the ER. Here’s an example of how \(p_N(\cdot)\) changes with \(\lambda\).
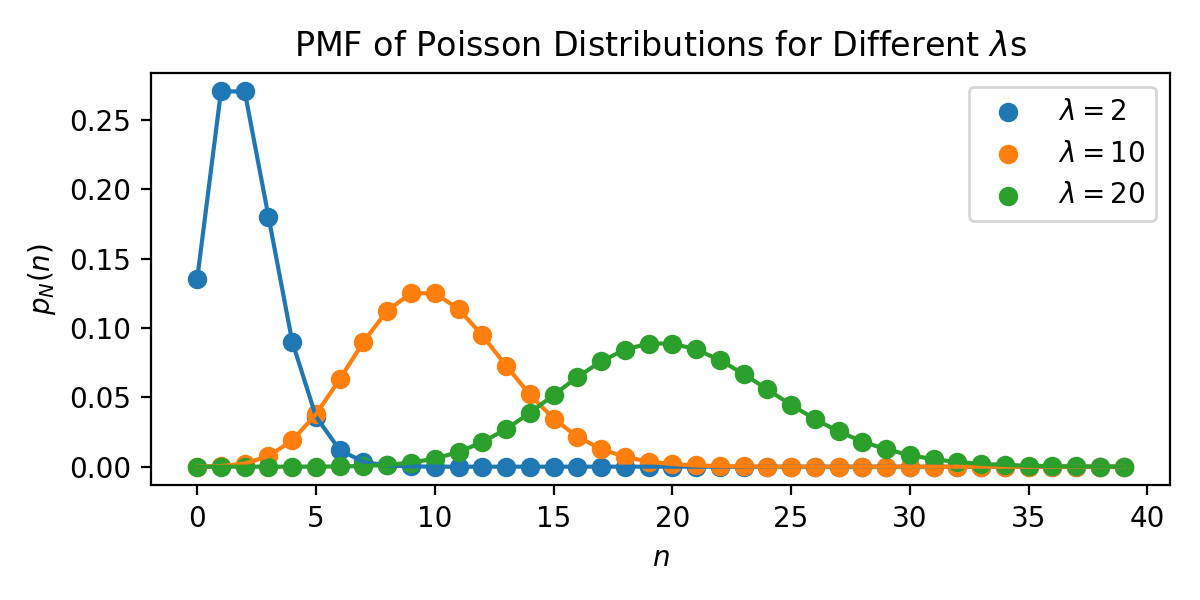
Fig. 4.1 PMF of a Poisson RV with different values of \(\lambda\).#
Independent, Identically Distributed (i.i.d): We say a variable is i.i.d if different observations of the same phenomenon are independent (i.e. that do not affect one another) and if they follow the same PMF. For example, when we flip a coin, previous flips do not affect future flips (i.e. if the coin landed heads, it does not affect its probability of landing heads next), and every time we flip the coin, the probability of it landing heads is the same (so it’s identically distributed). In contrast, suppose we’re monitoring a patient’s vitals (like heart rate) in the Intensive Care Unit of the IHH. The patient’s heart rate now is not independent of their heart rate a moment ago; their heart rate now is likely close to their heart rate a moment ago.
Example: We the notation \(N \sim p_N(\cdot)\) signifies that, the number of beings coming to the ER is distributed according to distribution \(p_N(\cdot)\), and that \(N\) is sampled i.i.d.
Summary of Notation:
Let \(R\) denote an RV.
\(p_R(r)\) is the evaluation of the PMF at \(r\): i.e. what’s the probability that \(R\) equals the specific value \(r\)?
\(p_R(\cdot)\) is the PMF whole of \(R\)—that is, it represents the distribution before asking about the probability of \(R = r\).
\(R \sim p_R(\cdot)\) denotes that \(R\) is sampled i.i.d from \(p_R(\cdot)\).
Exercise: Gaining comfort with commonly-used discrete distributions
Part 1: Browse the Wikipedia pages for the following distributions:
Then, for each distribution,
Describe a random phenomenon from everyday life that can be described using the distribution.
Define a random variable for the phenomenon you described. Write the support and PMF for this random variable using the above notation.
Describe a setting of the distribution’s parameters that makes sense for your specific phenomenon (and explain why it makes sense).
Hint: On each Wikipedia page, there’s a panel on the right side that summarizes the properties of the distribution (e.g. its support, PMF, example plots, etc.).
We’ll get you started with the Bernoulli distribution (and you can do the rest):
The Bernoulli distribution models any random choice between two options. For example, it can model a coin flip.
Let \(H\) be the outcome of a random coin flip. Support: \(H \in S = \{0, 1\}\), where 1 is heads and 0 is tails. PMF: \(p_H(h) = \rho^h \cdot (1 - \rho)^{1 - h}\), where \(h \in S\) and \(0 \leq \rho \leq 1\).
For a fair coin, \(\rho = 0.5\), indicating that on average, half of all coin flips will result in heads and the other in tails.
Part 2: How do the following distributions relate to one another?
Bernoulli and Categorical
Bernoulli and Binomial
Bernoulli and Geometric
4.2. Matching the Distribution to the Scenario#
We’ll now start working with data from IHH’s ER. We’ll use a Python library called pandas to read in the data, which is stored as a .csv file:
# Import a bunch of libraries we'll be using below
import pandas as pd
import matplotlib.pylab as plt
import numpyro
import numpyro.distributions as D
import jax
import jax.numpy as jnp
# Load the data into a pandas dataframe
csv_fname = 'data/IHH-ER.csv'
data = pd.read_csv(csv_fname, index_col='Patient ID')
# Print a random sample of patients, just to see what's in the data
data.sample(15, random_state=0)
| Day-of-Week | Condition | Hospitalized | Antibiotics | Knots | |
|---|---|---|---|---|---|
| Patient ID | |||||
| 9394 | Friday | Allergic Reaction | No | No | 0 |
| 898 | Sunday | Allergic Reaction | Yes | Yes | 0 |
| 2398 | Saturday | Entangled Antennas | No | No | 3 |
| 5906 | Saturday | Allergic Reaction | No | No | 0 |
| 2343 | Monday | High Fever | Yes | No | 0 |
| 8225 | Thursday | High Fever | Yes | No | 0 |
| 5506 | Tuesday | High Fever | No | No | 0 |
| 6451 | Thursday | Allergic Reaction | No | No | 0 |
| 2670 | Sunday | Intoxication | No | No | 0 |
| 3497 | Tuesday | Allergic Reaction | No | No | 0 |
| 1087 | Monday | High Fever | Yes | No | 0 |
| 1819 | Tuesday | High Fever | Yes | No | 0 |
| 2308 | Tuesday | Allergic Reaction | No | No | 0 |
| 6084 | Monday | High Fever | No | No | 0 |
| 3724 | Tuesday | Allergic Reaction | Yes | Yes | 0 |
As you can see, the data contains several variables:
Patient ID. A unique ID for identifying IHH ER patients. Don’t worry, the IDs have already been de-anonymized, meaning that they cannot be used to connect back to the patient’s medical records.
Condition. What the patient came to the ER for. As you can see, there are a variety of reasons intergalactic beings come to the IHH’s ER!
Hospitalized. Whether the patient was hospitalized (yes or no).
Antibiotics. Whether the patient was given antibiotics (yes or no).
Knots. For patients coming to the ER because of entangled antennas, this is the number of knots.
Exercise: Visualizing the distribution of each variable
Use pandas and matplotlib to visualize the distribution of each variable. You may have to do some googling around to determine which library calls are appropriate for each variable.
Note: Patient ID is not a variable.
We’ll start you off by visualizing the distribution of patients arriving on each day of the week:
# Visualize the distribution of conditions at the IHH ER
# Compute the percentage of patients with each condition
counts = data['Day-of-Week'].value_counts(sort=True, normalize=True)
# Put the names of the variables in to x, and the percentage into y
x = []
y = []
for variable, probability in counts.items():
x.append(variable)
y.append(probability)
# Plot!
plt.bar(x, y)
# Add axis labels and titles
plt.xticks(rotation=30)
plt.xlabel('Day of Week')
plt.ylabel('Probability')
plt.title('Distribution of Patients by Day at the IHH ER')
plt.show()
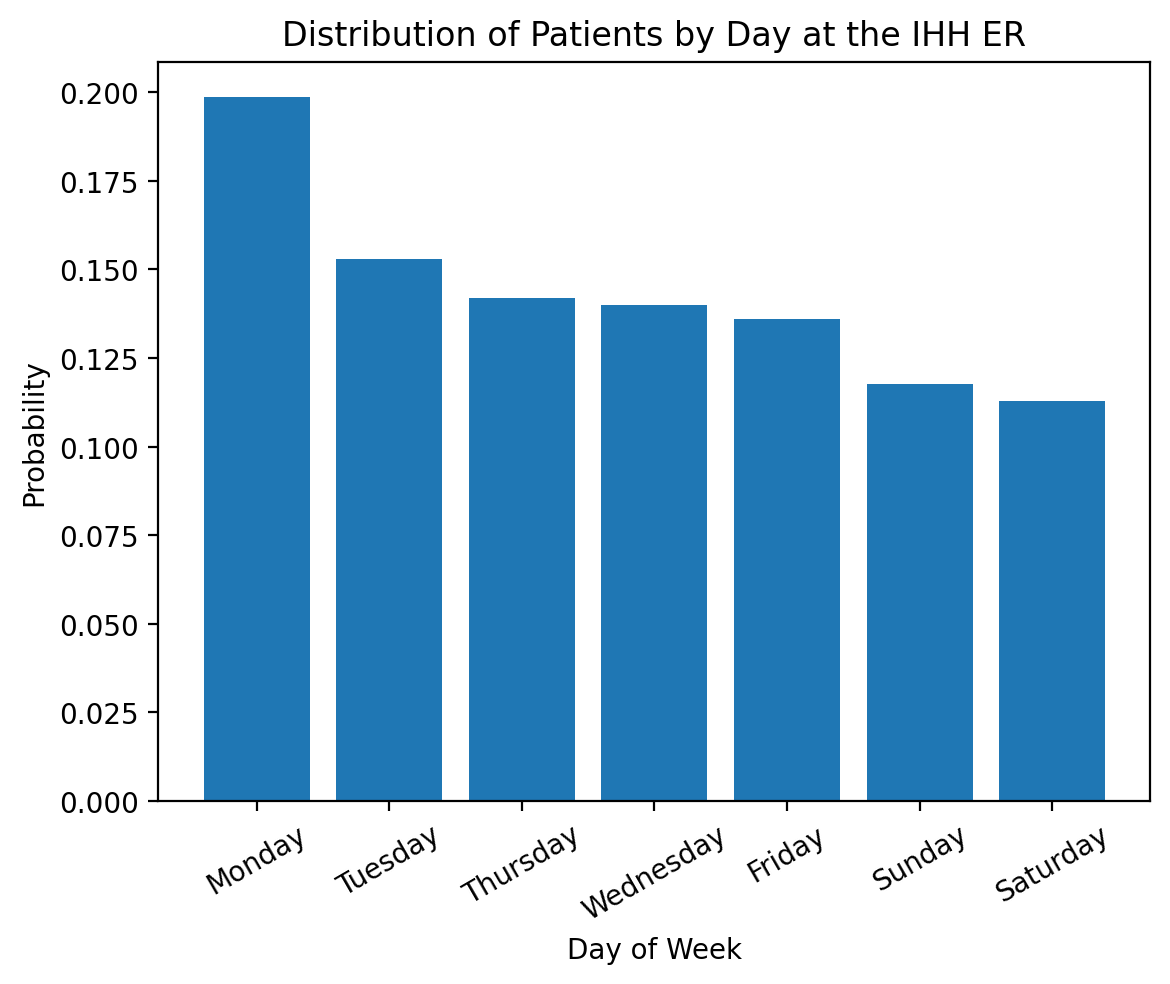
Exercise: Matching the distributions to the data
Determine which distribution from the list above best matches each variable in the data. How did you decide which one to choose? Please justify your choice with the support and PMF of the distribution.
Are the matches you selected perfect? If not, how are they lacking?
What kind of information do we miss out on when considering each variable separately? For this question, pick one example of a variable you recommend the IHH considers jointly with another variable. Explain why it’s important not to look at this variable alone, backing up your claim with a plot.