15. Neural Networks#
# Import some helper functions (please ignore this!)
from utils import *
Context: So far, we’ve focused on translating our IHH colleague’s goals into probabilistic models, and then fitting these models to data to help them answer scientific questions. In each model’s conditional distributions, we’ve had to make two choices: what distribution to use, and how the distributions parameter should depend on the condition. For example, in regression, recall we picked the following conditional distribution:
where \(\mu(x_n; W)\) represents the “trend” of the data. We’ve had to decide whether \(\mu(x_n; W)\) should be linear, polynomial, or some other function. As our data grows in complexity—for example, as \(x_n\) becomes high-dimensional—it becomes increasingly difficult to make up functions that are, expressive, fast, and easy to code. We will show you why below.
Challenge: So what functions should be use in our probabilistic models? Here, we will introduce a new type of function—a neural network. As we will show here, neural networks are expressive, fast, and easy to code.
Outline:
Shortcomings of other expressive functions, likely polynomials
The idea behind neural networks: using function composition to create expressive functions
Introduce a little bit of linear algebra to help introduce neural networks
Introduce neural networks, implement them in
NumPyroand fit them to IHH dataConnect the math behind neural networks to the pictures used to represent them in popular media
15.1. The Shortcomings of Polynomials#
The Universality of Polynomials. In both chapters about regression and classification, we observed the benefits of using non-linear functions for data with non-linear trends. In regression, we’ve focused on polynomials as our primary tool for creating non-linear functions, and for our low-dimensional data, they seemed to work great! So you may be wondering, why not apply them to high-dimensional data as well? In fact, polynomials boast a very powerful property: they are universal function approximators. By this, we mean that for any continuous function on some bounded interval \([a, b]\), we can find a polynomial that approximates it arbitrarily well (this is known as the Stone–Weierstrass theorem). This means that for any data set that consists of continuous trends, theoretically speaking, polynomials can capture it. This is a huge deal! So let’s see how polynomials measure up against a neural network:
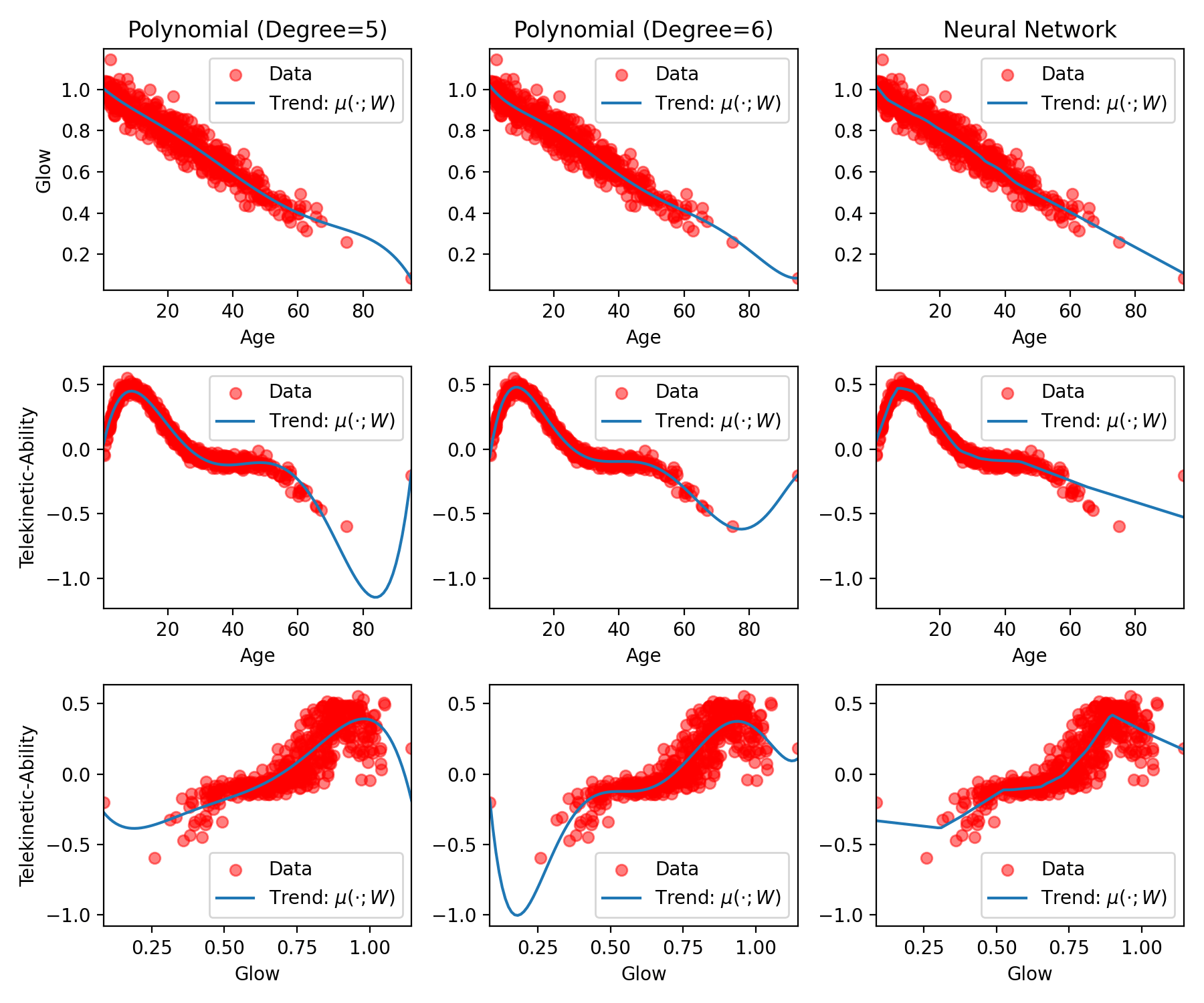
Fig. 15.1 Examples of polynomial and neural network regression on IHH data.#
As you can see, polynomial regression seems to capture the trend in these regression data sets super well—so why aren’t they as famous as neural networks? Polynomial regression actually comes with several challenges that make it inappropriate in many contexts.
Challenge 1: Numerical Instability. Polynomials are numerically unstable. Imagine you want to use a degree-20 polynomial in your regression model. This means that, in fitting your model, you will have to evaluate \(x^{20}\). When \(x = 0.1\) and when \(x = 10.0\), you’re asking your computer to represent numbers like \(0.000000000000000000001\) and \(1000000000000000000000\). Because your computer only has finite precision, very small numbers are at risk of being rounded down to \(0\) and very large numbers may overflow.
Challenge 2: Inductive Bias. Oftentimes, we’re less interested in seeing what our model does on data we’ve already observed. Instead, we want to know what it might do for a new data point. For example, suppose we’re asked to develop a model to predict telekinetic ability and glow from age (like we did in the regression chapter). We aren’t interested in seeing the model’s predictions on patients included in our data set—we’ve already observed these patients’ age, telekinetic ability, and glow. What we’re we’re interested in is the model’s predictions for new patients. For example, what happens if we get an input that we’ve never seen before, like a patient that’s much older or younger than the rest of the patients in the data.
We call the trend of the model away from the data its “inductive bias.” Different models that fit the data equally well may actually have different inductive biases. Let’s illustrate what we mean visually. In the plot above, you see that the 5th and 6th-degree polynomials both fit the data equally well. But what would they predict for points away from our data? And will their predictions be medically reasonable? Let’s have a look: the plot below shows the very same models from the plot above, but this time the plots are zoomed out. In this way you can see each model’s behavior away from the data. As you can see, each model’s inductive bias is different.
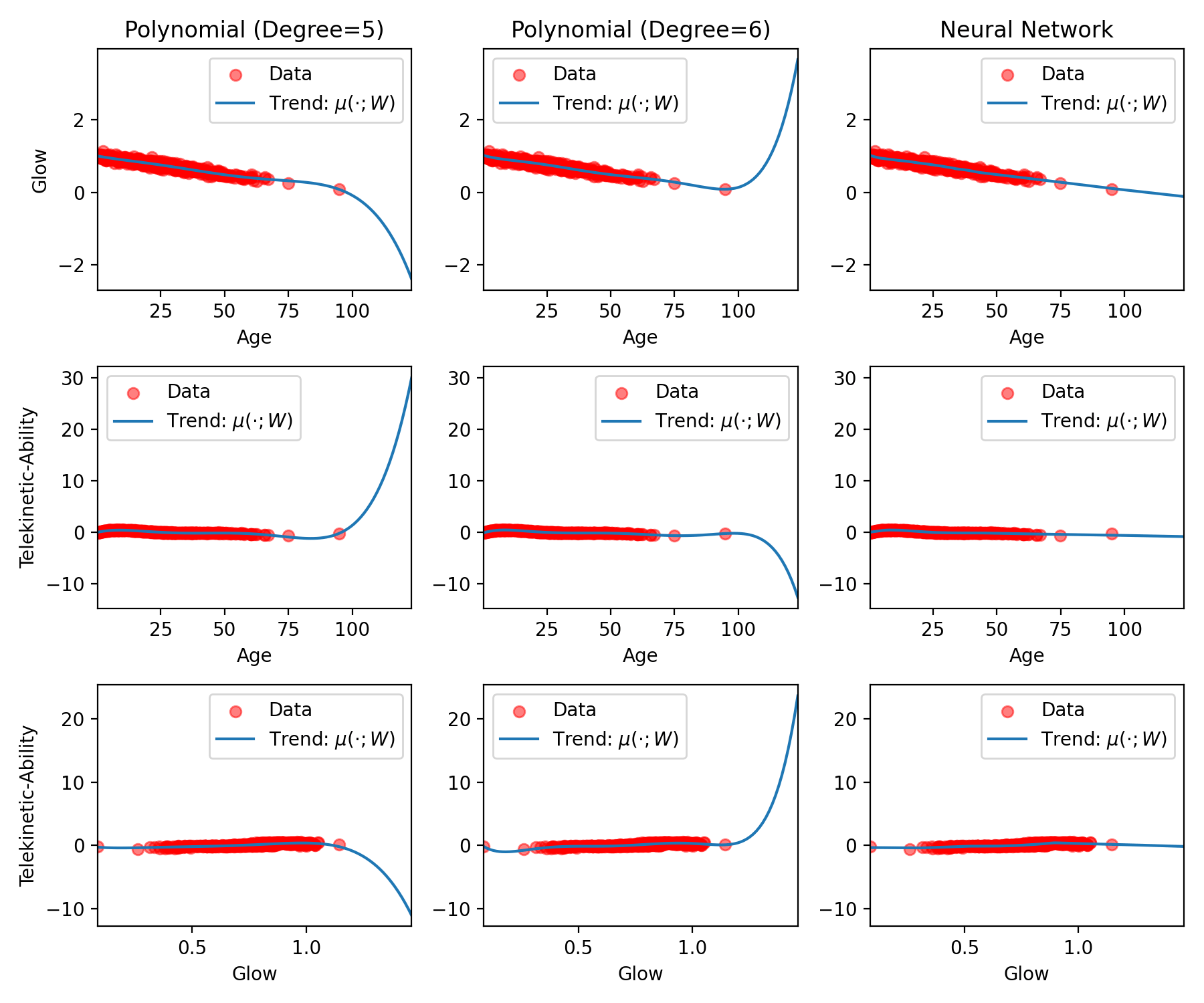
Fig. 15.2 A zoomed-out plot of the same models from the figure above.#
What’s interesting in the above plot is that the polynomial regression’s inductive bias tends towards positive or negative infinity very quickly. Looking at the math, this makes sense: a 5th or 6th-degree polynomial will include terms like \(\text{age}^5\), which grow quickly with age.
While this may be the desired behavior for some data sets, for our data sets, it’s inappropriate. For example, look at the left-middle plot, in which the 5th-degree polynomial regression predicts telekinetic ability from age. Even though we’ve generally seen that as age increases, telekinetic ability decreases, this plot suggests the opposite. After age 100, the patient’s telekinetic ability skyrockets; in fact, it increases so quickly it’s larger than the ability of all other patients. While in comparison, the neural network’s inductive bias doesn’t seem obviously inappropriate, that doesn’t mean that it is appropriate. It’s important to remember that neural networks, like any other function, have inductive biases that are useful for some tasks and not for others.
Conclusion: When picking a function-class to work with (like the class of polynomials), it’s important to consider numerical stability (as well as ease of optimization). Without these properties, it doesn’t matter how expressive your function is, since you’ll never be able to practically fit it to data. Second, it’s important to think about the function class’s inductive bias, or in other words, to think about how it will generalize in regions of the space where data is scarce.
15.2. Expressive Functions from Simple Building Blocks#
Idea. Instead of using polynomials, let’s see if we can build an expressive function-class, \(\mu(\cdot; W)\), from small building blocks. Each block will be simple and numerically stable. And when combined, will give us an expressive function, capable of adapting to any trend we observe in the data. This is the mechanism underlying neural networks.
Let’s import some libraries so we can plot as we go.
import jax.numpy as jnp
import jax.random as jrandom
import jax.nn as jnn
import numpyro.distributions as D
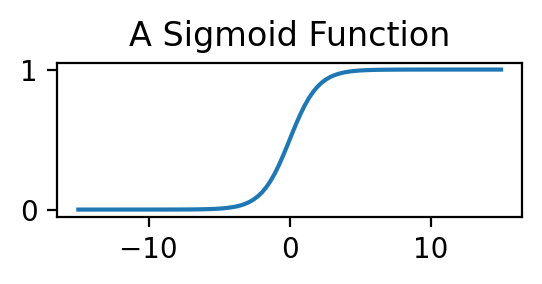
A Simple Block. For the simple block, let’s use a sigmoid. A sigmoid looks like a smoothed-out step function:
plt.figure(figsize=(3, 1))
# Domain on which to visualize our functions
x = jnp.linspace(-15.0, 15.0, 100)
# Plot the sigmoid
plt.plot(x, jnn.sigmoid(x))
plt.title('A Sigmoid Function')
plt.show()
We will give the sigmoid two parameters, which we will learn from data, giving us our simple building block:
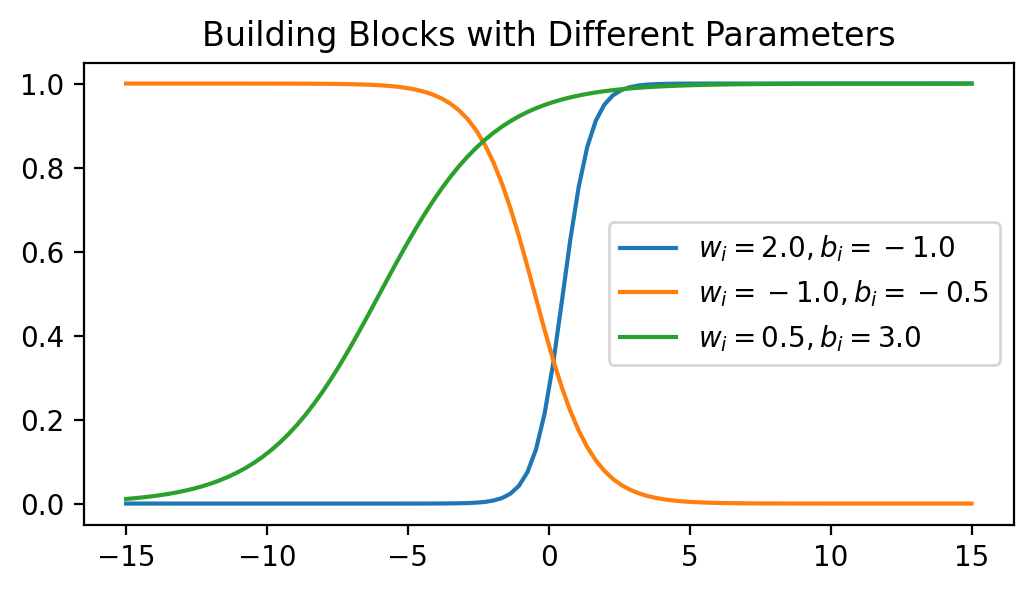
Here, \(b\) shifts the sigmoid left/right, and \(w\) stretches/shrinks the overall sigmoid horizontally. Let’s see what this looks like for different choices of choices of \(w\) and \(b\):
# Choose some scales and shifts
scale = [2.0, -1.0, 0.5]
shift = [-1.0, -0.5, 3.0]
# Plot!
plt.figure(figsize=(6, 3))
# Domain on which to visualize our functions
x = jnp.linspace(-15.0, 15.0, 100)
# For each set w, b plot the function
for w, b in zip(scale, shift):
plt.plot(x, jnn.sigmoid(w * x + b), label=r'$w_i = {}, b_i = {}$'.format(w, b))
plt.title('Building Blocks with Different Parameters')
plt.legend()
plt.show()
Of course, the above example is only for a 1-dimensional input. Ideally, our function class will work for higher-dimensional inputs. We can incorporate this into our simple block as follows. We define \(D_x\) to be the dimension of the inputs, \(x\), and we sum over the scaled and shifted inputs as follows:
where \(x^{(d)}\) denotes the \(d\)-th dimension of \(x\), and \(w = \{ w_1, \dots w_d \}\) and \(b = \{ b_1, \dots b_d \}\) have a different scale and shift for every dimension.
This unassuming building block, \(u(x; w, b)\), is actually called a neuron. We will next start combining these neurons to form a full neural network.
Combining Building Blocks via Addition. As we’ve seen when plotting our building block (or neuron), it can’t really model anything too interesting. However, by adding these neurons together with different parameters, we can start making more interesting-looking functions. To get some intuition, let’s start with a simple experiment—we’ll add the three neurons from the plot above and see what kind of function we get:
# Domain on which to visualize our functions
x = jnp.linspace(-15.0, 15.0, 100)
# Compute the sum of the blocks
y = 0.0
for w, b in zip(scale, shift):
y += jnn.sigmoid(w * x + b)
# Plot!
plt.figure(figsize=(4, 2))
plt.plot(x, y)
plt.title('Sum of Three Neurons')
plt.show()
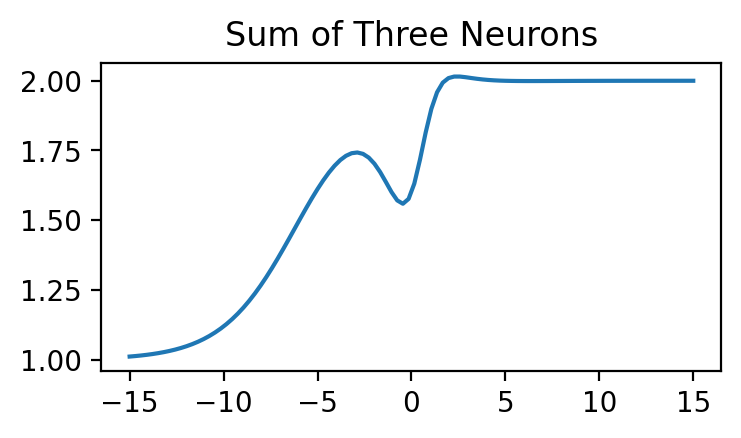
As you can see, this function already looks a lot more interesting than a sigmoid on its own. So how can we continue to expand the flexibility of our function? We can apply the same logic. That is, we can scale and shift our neurons and sum them up. In doing so, we end up with functions that are more expressive than each individual neuron. Formally, we will sum over a group of \(H\) of these neurons as follows:
where
So what kind of functions can be captured by \(f(\cdot; W, b)\)?
Let’s plot functions composed of \(H = 30\) neurons.
So that we don’t have to pick values of \(W\) and \(b\) by hand, let’s draw them from some distribution. Here, we’ll go with a Normal distribution.
We’ll repeat the process \(N\) times to get a sense of the variety of functions \(f(\cdot; W, b)\) can represent.
Let’s see what happens:
# Number of building blocks to add
H = 30
# Number of functions to plot
N = 50
# Domain on which to visualize our functions
x = jnp.linspace(-3.0, 3.0, 100)
# Create one random key per function
key = jrandom.PRNGKey(seed=0)
key_per_function = jrandom.split(key, N)
plt.figure(figsize=(5, 3))
for k in key_per_function:
key_W_in, key_W_out, key_b_in, key_b_out = jrandom.split(k, 4)
# Generate the parameters of the block from a Normal distribution
W_in = D.Normal(0.0, 20.0).sample(key_W_in, (H, 1))
b_in = D.Normal(0.0, 20.0).sample(key_b_in, (H, 1))
W_out = D.Normal(0.0, 3.0).sample(key_W_out, (H, 1))
b_out = D.Normal(0.0, 1.0).sample(key_b_out, (H, 1))
# Use some "broadcasting" magic to efficiently sum the building blocks
f = (W_out * jnn.sigmoid(W_in * x + b_in) + b_out).sum(axis=0)
# Plot!
plt.plot(x, f, alpha=0.3, color='blue')
plt.xlabel(r'$x$')
plt.ylabel(r'$f(x; W, b)$')
plt.title('Adding Scaled and Shifted Neurons')
plt.show()
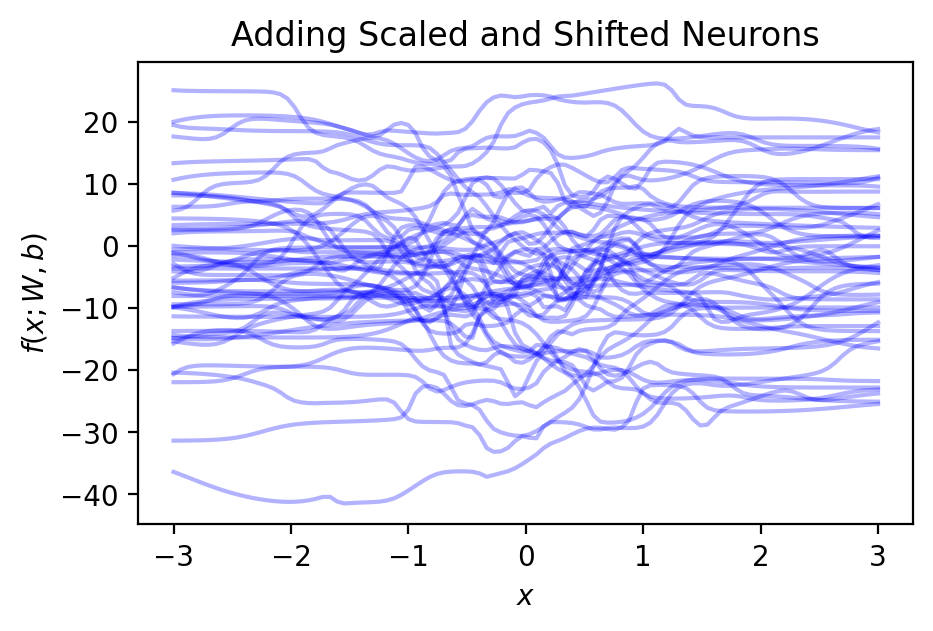
Now we’re getting wiggly! Given how many different functions \(f(\cdot; W, b)\) can represent, you can imagine that by learning the parameters, \(W\) and \(b\), from data, we can capture the data trends accurately. Moreover, notice that, unlike polynomials, there’s nothing about \(f(\cdot; W, b)\) that is numerically unstable. Each neuron is a sigmoid, so its range is between \([0, 1]\); therefore, summing up the sigmoids together to get \(f(\cdot; W, b)\) doesn’t blow up like a polynomial.
The function we arrived at, \(f(\cdot; W, b)\), is called a neural network (of “width” \(H\). We can plug it into our regression or classification models and learn the parameters, \(\theta = \{ W, b \}\), via MLE.
Combining Building Blocks via Composition. We can make the neural network we’ve created so far even more expressive by repeating the same idea. We treat each neural network as our new “building block.” Then, just like before, we scale and shift them, and add them up. Every repetition of this process adds another “layer” to the neural network, making it “deeper”—the number of layers is known as the depth of the network.
We won’t notate all of this with math, because it gets cumbersome unless we introduce some additional notation (this is what we’ll do next). You can imagine though, the deeper the network, the more expressive it will be.
Activation Functions. Here, we chose to use a sigmoid in our neuron. There are many functions we could have used instead, each giving us different neural networks with different inductive biases. These functions are generally called “activation functions.” Wikipedia organized a table of them, and many of them are already implemented in Jax (see here).
The name “activation function” comes from the inspiration from neuroscience that led to neural networks.

Fig. 15.3 Inspiration behind the “neuron” in a neural network. Figure taken from this paper.#
As you can see from the figure, each neuron takes signals from its inputs (by summing over the scaled and shifted inputs). The sum is then passed on to the activation function, which only “activates” (or sends a non-zero value) if the sum is sufficiently large. Looking at the shape of the sigmoid activation function, for example, you can see exactly the input value for which the sigmoid would output a non-zero value. You can learn more about the connection between artificial and biological neurons here.
15.3. Efficient Representations via Matrices#
So how can we code a neural network in a way that’s (a) easy to code, and (b) efficient for the computer to evaluate? We’ll now use some tricks from linear algebra—matrices—to help us out. Considerable research and engineering has gone into allowing your computer to multiply matrices fast. By relying on this prior work, we can implement our neural networks easily and efficiently. If you haven’t taken linear algebra before, that’s no problem. We’ll walk you through exactly the parts you need to know to implement your own neural network.
What’s a Matrix? For our purposes, you can think of a matrix as a 2-dimensional array. Here are some examples of matrices:
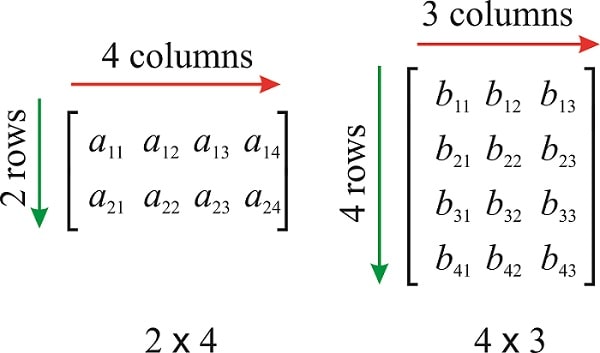
Fig. 15.4 Two matrices, \(A\) and \(B\), taken from this website.#
We say that the matrix \(A\) (on the left) is a 2-by-4 matrix, since it has 2 rows and 4 columns. Similarly, the matrix \(B\) (on the right) is a 4-by-3 matrix.
Matrix Multiplication. To multiply two matrices, we take each row of the first matrix and each column of the second and proceed as follows:
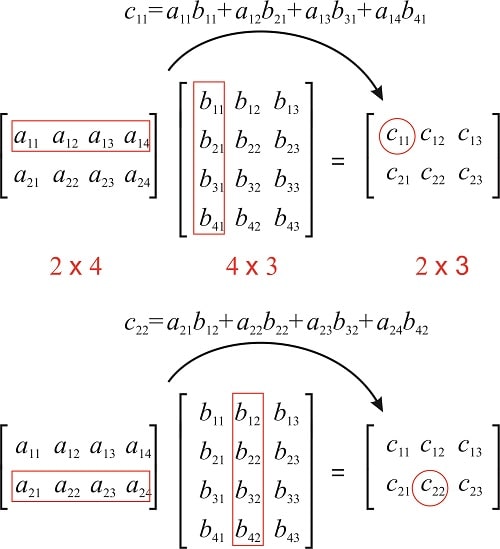
Fig. 15.5 Matrix multiplication, \(A \cdot B = C\), taken from this website.#
As you can see from the figure above, the number of rows in \(A\) must match the number of columns in \(B\). Moreover, each element \(c_{i, j}\) in matrix \(C\) represents the following sum of products:
where \(j\) indexes into each element in the row of \(A\) and the corresponding element in the column of \(B\). Next, we’ll make the connection between matrices and neural networks.
So why is matrix multiplication defined this way? What are properties of matrices? That’s beyond the scope of this course.
Sums of Shifted and Scaled Numbers via Matrix Multiplication. You may have noticed that in our neural network math so far, there’s a pattern that keeps popping up. We keep summing over things that we’ve scaled and shifted. You can see this in the definition of a single neuron, \(u(x; w, b)\), in the definition of a simple neural network, \(f(x; W, b)\), as well as in the process of creating deeper networks. These sums look very much like the formula for \(c_{i,j}\) above. As such, we can represent this operation using matrix multiplication.
15.4. Neural Networks#
A 1-Layer Neural Network. Let \(D_x\) be the dimension of our inputs, \(x\), and let \(D_y\) be the dimension of our outputs, \(y\). We can now rewrite our definition of a neural network using matrices. Our neural network will consist of the following recipe:
Scaling the inputs. We scale each dimension of the inputs, \(x\), by \(H\) different values. This can be done using a matrix \(W_0\) of dimensions \(D_x \times H\). This gives us: \(x \cdot W_0\).
Shifting the inputs. We shift each of the values from the previous steps. This can be done by adding an array/vector, \(b_0\) of dimension \(H\) to the result from the previous step: \(x \cdot W_0 + b_0\). These are our scaled and shifted inputs.
Applying the activation. We apply an activation function to the result from the previous step. We can use a sigmoid like before, or any other activation function we choose. For generality, we’ll call it \(g(\cdot)\). This gives us \(H\) different neurons: \(g(x \cdot W_0 + b_0)\).
Scaling and shifting the outputs. Recall that we get expressivity by adding scaled and shifted neurons together. To do this, we’ll introduce \(W_1\) and \(b_1\), for scaling and shifting, respectively. \(W_1\) has dimensions \(H \times D_y\) and \(b_1\) has dimensions \(D_y\). Altogether, this gives us the following formula:
(15.7)#\[\begin{align} f(x; \underbrace{W_0, W_1, b_0, b_1}_{\text{parameters, } \theta}) = g(x \cdot W_0 + b_0) \cdot W_1 + b_1. \end{align}\]The number of neurons, \(H\), is called the hidden dimension of the neural network.
Deeper Networks. We can extend the above network by adding as many additional layers as you like:
Note that in these neural networks, we always have that:
The \(W\) and \(b\) applied to the inputs is always of dimensions \(D_x \times H\) and \(H\), respectively.
The \(W\) and \(b\) applied to the outputs is always of dimensions \(H \times D_y\) and \(D_y\), respectively.
The \(W\)’s and \(b\)’s in the middle of the network are always of dimension \(H \times H\) and \(H\), respectively.
Exercise: Neural Network Regression
Load in data/IHH-CTR-CGLF-regression-augmented.csv. Your goal is to predict telekinetic ability from age.
Part 1: Take your polynomial regression model, implemented for the chapter on regression. Swap out the polynomial \(\mu(\cdot; W)\) with your implementation of a 1-layer neural network. Your neural network implementation should use the matrix formulation above. Use a sigmoid activation function. Please use the following function signature:
def model_neural_network_regressor(N, x, y=None, H=20):
pass # TODO implement
Tips:
To multiply matrices, use
jnp.matmul—documentation here.Both your inputs and your outputs should have shape
(N, 1)forjnp.matmulto work correctly.Since you’re now passing in data as 2-dimensional arrays, you’ll need to use the following notation for your plate:
with numpyro.plate('data', N, dim=-2): pass # TODO implement
The additional keyword argument,
dim=-2, tellsNumPyrowhich dimension of the input isN. That is, in the tuple,(N, 1),dim=-2refers toN, anddim=-1refers to1.Finally, since neural networks have lots of parameters, it’s good to try initializing them to different values when optimizing. Instead of specifying the initial values by hand, like we’ve done before, follow the template below:
W0 = numpyro.param( 'W0', lambda key: 0.1 * jrandom.normal(key, shape=(1, H)), # Initialize to a Gaussian of shape (1, H) constraint=C.real, )
Part 2: Fit your neural network regression model to the data using MLE using a different number of neurons, \(H \in \{2, 16, 32, 64 \}\). For each value of \(H\), use 3 different keys (passed into the optimizer)—this, will give you several different initializations, each yielding slightly different fits.
Part 3: Visualize samples from each neural network regression and each initialization against the training data. How does your network behave as you increase \(H\)? How are the model fits different across different initialization? For both, your answer should look both at how your model interpolates and extrapolates (how it fits the data, and what it does away from the data).
Part 4: Replace your activation function with a ReLU activation and repeat steps (2) and (3). How does this new activation function affect the network’s fit?
Types of Neural Networks. In addition to the neural networked we introduced here, often called a “fully connected” or “dense” neural network, there are many other types of neural network. Each type specializes in a different data modality. To name a few, Convolutional Neural Networks are suitable to image data, and Recurrent Neural Networks are suitable for time-series data or natural language data. The recent advances in deep learning that enabled Large Language Models like ChatGPT are all due to a type of neural network called a Transformer. We will not get into these here. Instead, we will treat these as tools we can freely incorporate into our probabilistic models to make our models more expressive as we see fit.
15.5. Challenges with Neural Networks#
Optimization. As your model becomes more expressive, optimization typically becomes more difficult. Our loss function will have many more local optima and strange geometry that make it practically impossible for an optimizer to find the global optima. For complicated models, it’s therefore important to remember the flaws of numerical optimization, and to treat optimization like a research problem. By this, we mean that when you encounter a problem—e.g. your model doesn’t optimize, your loss bounces up and down erratically, etc.—you should approach it like a scientist. You should form hypotheses about the shape of the loss function. These hypotheses should inform how you adjust your learning rate (and other optimization hyperparameters), the number of parameter initializations you try, etc. Please review the chapter on optimization for more intuition on how gradient-based optimization behaves on different loss functions.
Of course, there are many ML researches working hard to try to understand these optimization challenges:
The paper, Visualizing the Loss Landscape of Neural Nets, introduces a new way of visualizing high dimensional loss functions of neural networks, and explores how neural network architecture (or “type”) makes optimization easier or harder. This paper also led to further inspiration for more artistic visualizations of loss landscapes.
Conventional wisdom says that it’s important to find the global optima for good model performance. As many papers have already shown, numerical optimizers that often get stuck in a variety of local optima actually benefit model performance. The paper Disentangling the Mechanisms Behind Implicit Regularization in SGD attempts to understand why.
Conventional wisdom also says that when neural networks become significantly larger than what’s needed to make good predictions on the data, they overfit and become difficult to optimize. The paper, Deep Double Descent: Where Bigger Models and More Data Hurt, shows that, in contrast to this conventional wisdom, larger models actually perform better. This phenomenon is called “double descent”—model performance initially gets worse as the neural network becomes larger, but past a certain neural network size, it improves again.
Interpretability. As models become more complicated, it also harder to intuit about their inner workings. Check out this in-browser neural network training visualization. You can play with different neural network sizes, activation functions, etc. The visualizer will then show you the output of every neuron in the neural network. As you increase the size of your neural network, can you make sense of what each individual neuron is doing? It’s very difficult to understand neural networks by looking at their parameters… But when ML models touch human lives, we often need to understand the “reasoning” behind an ML model’s prediction. Understanding the model’s reasoning is important for several reasons:
Models can be incorrect and discriminatory. We need to be able to verify the model’s output before making decisions on it. For example, in many medical imaging contexts, ML models can learn to make predictions based on the demographic proxies hidden in the image, rather than based on the physiological content of an image.
Models don’t understand context. Sometimes, we need to synthesize a model’s output with additional information about our decision-making context. For example, what if a model prescribes penicillin to a patient who’s allergic it?
Humans need a mechanism for recourse under AI systems. For example, if an AI system decides whether you qualify for a loan from the bank, wouldn’t you like to know what you can do to alter the AI’s decision?
When something goes wrong with an automated system, who takes responsibility? For legal reasons, it’s often argued that a model should only make recommendations to a human user, who will make the final decision. In this way, the human can be held responsible for any negative outcomes (do you think this is reasonable?).
To address all of the above challenges, “interpretable ML” or “explainable AI” has emerged as an exciting field of research. Since interpretability is a human-facing property of ML systems, this field draws on both ML and human-computer interaction (HCI)—you may enjoy the paper, Towards A Rigorous Science of Interpretable Machine Learning. Of course, interpretable ML has its own challenges (this is why it is an active area of research!)
Explanations of ML models can be misleading. In the paper, How machine-learning recommendations influence clinician treatment selections: the example of antidepressant selection, the authors found that clinicians interacting with incorrect recommendations paired with simple explanations experienced a significant reduction in treatment selection accuracy.
Explanations of ML models can be manipulative. In the paper, Explaining Models: An Empirical Study of How Explanations Impact Fairness Judgment, the authors show that the type of explanation shapes our judgement of fairness.
Explanations can fail when integrated into the broader sociotechnical system. For example, in the paper, “If it didn’t happen, why would I change my decision?”: How Judges Respond to Counterfactual Explanations for the Public Safety Assessment, explanations of an AI system were entirely ignored by human users.
The Guise of Objectivity. Because neural networks are so expressive, as a society, we’ve crafted a narrative about their objectivity—that they are able to recover objective truths in a purely data-driven fashion, no human-assumptions necessary. However, this is not theoretically or practically possible. All models make assumptions that have significant downstream consequences. Some models, like neural networks, however, are complicated enough to better hide their underlying assumptions. This means we have to be extra careful when reasoning about them. As an example, the paper Neural Tangent Kernel: Convergence and Generalization in Neural Networks shows that, under mild conditions, neural networks trained with gradient descent actually behave like a type of regression, known as kernel regression. And kernel regression does make assumptions (that are in fact, in many ways easier to understand than those underlying a neural network).